IEEE 754 Floats
IEEE 754 Floats
IEEE 754 Floats
Cấu trúc số thực trong IEEE 754, Một số thực được lưu bằng ba phần:
- Sign (1 bit): cho biết số dương (0) hay âm (1).
- Exponent (mũ): lưu phần mũ, có thêm “bias” để biểu diễn số nhỏ hơn 1.
- Mantissa (hay fraction): lưu phần trị số chính xác.

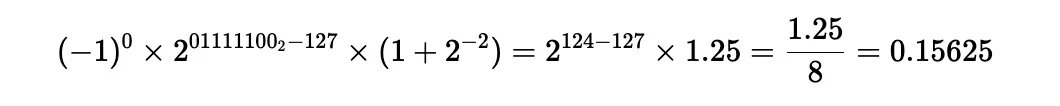
Các dạng phổ biến:
| Loại (Type) | Bit dấu (Sign) | Bit mũ (Exponent) | Bit trị số (Mantissa) | Tổng số bit (Total bits) | Số chữ số thập phân xấp xỉ |
|---|---|---|---|---|---|
| single | 1 | 8 | 23 | 32 | ~7.2 |
| double | 1 | 11 | 52 | 64 | ~15.9 |
| half | 1 | 5 | 10 | 16 | ~3.3 |
| extended | 1 | 15 | 64 | 80 | ~19.2 |
| quadruple | 1 | 15 | 112 | 128 | ~34.0 |
| bfloat16 | 1 | 8 | 7 | 16 | ~2.3 |
Các mức hỗ trợ phần cứng
-
Single và Double precision: Hầu hết CPU đều hỗ trợ hai loại này. Trong ngôn ngữ C, chúng tương ứng với kiểu float và double.
-
Extended formats: Chỉ có trên kiến trúc x86, trong C gọi là long double. Trên CPU Arm thì long double thực chất chỉ là double. Việc chọn 64 bit mantissa giúp biểu diễn chính xác mọi số nguyên kiểu long long. Ngoài ra còn có định dạng 40-bit với 32 bit mantissa.
-
Half precision (16-bit): Hỗ trợ rất ít phép toán, thường dùng trong machine learning, đặc biệt là mạng nơ-ron, vì cần tính toán khối lượng lớn nhưng không đòi hỏi độ chính xác cao.
-
Bfloat16: Dần thay thế half. Nó hy sinh 3 bit mantissa để có cùng phạm vi với single precision, giúp dễ tương thích. Chủ yếu được dùng trên phần cứng chuyên dụng: TPU, FPGA, GPU. Tên gọi “Brain float” xuất phát từ ứng dụng trong AI.
Sự bùng nổ của deep learning (tính toán ma trận khổng lồ) tạo ra nhu cầu lớn về nhân ma trận với độ chính xác thấp.
- Google phát triển TPU chuyên nhân ma trận bfloat16 kích thước 128×128.
- NVIDIA thêm tensor cores vào GPU mới, có thể nhân ma trận 4×4 chỉ trong một bước.
Handling Corner Cases
Trong số nguyên, chia cho 0 thường gây crash. Nhưng với số thực IEEE 754, có cách xử lý khác.
👉 Ví dụ thực tế: Năm 1996, chuyến bay đầu tiên của tên lửa Ariane 5 kết thúc bằng vụ nổ thảm khốc. Nguyên nhân: lỗi chuyển đổi số thực sang số nguyên (overflow). Hệ thống điều hướng nghĩ rằng tên lửa lệch hướng và tự điều chỉnh mạnh, dẫn đến vỡ vụn một tên lửa trị giá 200 triệu USD.
Cách CPU xử lý ngoại lệ khi xảy ra lỗi số học:
- CPU ngắt chương trình.
- Đóng gói thông tin vào cấu trúc gọi là interrupt vector.
- Chuyển cho OS, OS gọi đoạn mã xử lý (nếu có) hoặc kết thúc chương trình.
Cơ chế này phức tạp và khá chậm, không phù hợp cho hệ thống thời gian thực (ví dụ: điều khiển tên lửa).
…
Bài tập
Câu hỏi tư duy
- Tại sao
0.1 + 0.2 != 0.3trong float? Giải thích bằng binary representation của 0.1. - So sánh
==giữa hai float có an toàn không? Khi nào dùng được, khi nào phải dùng epsilon? - Một function tính
(a + b) + cvàa + (b + c)có cho cùng kết quả với double không? Giải thích tại sao FP không associative. bfloat16có cùng exponent range nhưfloat32nhưng ít mantissa hơn. Trade-off đó ảnh hưởng gì đến training mạng neural? Tại sao ML chấp nhận được?- Subnormal (denormal) numbers là gì? Tại sao chúng làm code chậm 100x trên một số CPU?
- NaN có những property kỳ lạ nào?
NaN == NaNtrả về gì? Cách check NaN đúng?
Bài tập code
Bài 1: Viết function so sánh 2 float “gần bằng nhau” với epsilon hợp lý:
bool nearly_equal(float a, float b);Bài 2: Tính tổng 1/i cho i = 1..10^7 hai cách:
- (a) Forward:
s += 1.0/ifrom i=1 to N. - (b) Backward:
s += 1.0/ifrom i=N to 1.
Cái nào chính xác hơn? Tại sao? So sánh kết quả với double precision summation.
Bài 3: Đo throughput của một loop có subnormal numbers vs normal numbers. Set FTZ (flush-to-zero) flag bằng _MM_SET_FLUSH_ZERO_MODE, đo lại.
Đáp án
Câu hỏi tư duy
-
0.1không có binary representation chính xác — giống như1/3trong base-10 =0.3333.... Trong binary,0.1≈0.0001100110011...(lặp vô hạn). Float lưu được ~7 digit chính xác → 0.1 thực tế ~0.10000000149011612. Cộng 2 số xấp xỉ → kết quả xấp xỉ ≠ 0.3 (cũng xấp xỉ). -
==an toàn khi: cả hai là kết quả của exact operations (e.g., gán literal int rồi convert), hoặc khi check special values (0.0, infinity, NaN). Không an toàn khi: kết quả của arithmetic, conversion, parsing. Dùng|a-b| < epsilon * max(|a|,|b|)(relative) hoặc ULPs comparison cho robust check. -
(a+b)+c ≠ a+(b+c)khi exponent khác nhau lớn. Ví dụ:a=1e20, b=-1e20, c=1→(a+b)+c = 0+1 = 1,a+(b+c) = 1e20-1e20 = 0(vì1e20+1=1e20do round-off). Đây là lý do-O3không tự reorder FP ops; cần-ffast-math. -
bfloat16: 1 sign + 8 exp + 7 mantissa. Range giống float32 (cùng 8 exp bit), precision thấp hơn (~3 decimal digit). ML chấp nhận được vì gradient noise lớn hơn floating-point error nhiều. Range quan trọng hơn precision — gradient có thể rất nhỏ hoặc rất lớn. fp16 có range hẹp → dễ underflow/overflow gradient → bfloat16 thắng cho training.
-
Subnormal: số rất nhỏ với exponent = 0, mantissa không normalized (không có hidden 1 bit). CPU thường handle subnormal qua microcode trap → chậm 50–100x. FTZ (flush-to-zero) làm subnormal → 0 → tránh trap. Quan trọng cho audio processing, simulation.
-
NaN:
NaN != NaNluôn true (NaN không bằng bất cứ gì, kể cả chính nó). Comparison với NaN luôn false. Check NaN:isnan(x)hoặcx != x. Bug điển hình: sort array có NaN → comparator return false cả 2 chiều → broken sort.
Bài tập code
Bài 1 — nearly_equal:
#include <math.h>#include <float.h>
bool nearly_equal(float a, float b) { if (a == b) return true; // handle infinity, exact match float diff = fabsf(a - b); float norm = fminf(fabsf(a) + fabsf(b), FLT_MAX); return diff < fmaxf(FLT_EPSILON, FLT_EPSILON * norm);}Ý nghĩa: dùng relative epsilon khi |a|, |b| lớn; absolute epsilon khi gần 0. FLT_MAX clamp tránh overflow khi a+b = inf.
Bài 2 — forward vs backward summation:
Backward chính xác hơn. Lý do: forward bắt đầu với s=1 (lớn), cộng 1/i rất nhỏ → s + 1/i ≈ s (lost precision). Backward bắt đầu với số nhỏ 1/N cộng với số nhỏ → giữ precision tốt hơn.
double sum_forward(int N) { double s = 0; for (int i = 1; i <= N; i++) s += 1.0 / i; return s;}
double sum_backward(int N) { double s = 0; for (int i = N; i >= 1; i--) s += 1.0 / i; return s;}Với N=10^7, sum thực ≈ 16.6953. Backward chính xác đến ~12 digits, forward ~10 digits. Kahan summation cho cả hai version chính xác như nhau (~15 digits).
double sum_kahan(int N) { double s = 0, c = 0; // c: compensation for (int i = 1; i <= N; i++) { double y = 1.0/i - c; double t = s + y; c = (t - s) - y; s = t; } return s;}Bài 3 — subnormal slowdown:
#include <xmmintrin.h> // SSE#include <pmmintrin.h> // SSE3
// Bật FTZ + DAZ (Flush-To-Zero + Denormals-Are-Zero)_MM_SET_FLUSH_ZERO_MODE(_MM_FLUSH_ZERO_ON);_MM_SET_DENORMALS_ZERO_MODE(_MM_DENORMALS_ZERO_ON);
// Loop với subnormalsfloat arr[N] = { 1e-39f, 1e-39f, ... }; // subnormal rangefor (int i = 0; i < N; i++) sum += arr[i] * arr[i];Trên Intel Skylake, subnormal multiply có thể chậm 50–100x. Bật FTZ → subnormal flush thành 0 → speed gần normal. Audio engines (real-time) thường bật FTZ globally.
Discussion
Sign in with GitHub to comment or react. Powered by giscus.