Memory Sharing
Memory Sharing
Memory Sharing
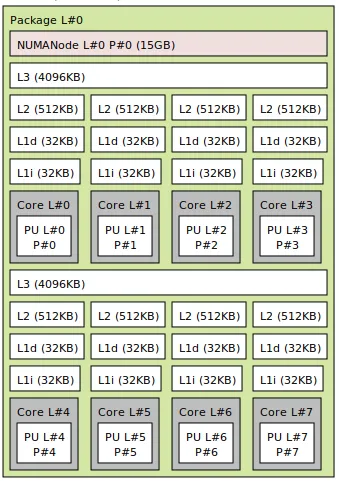
Trên hầu hết các CPU, chỉ có lớp cache cuối cùng (thường là L3) được chia sẻ, và không phải lúc nào cũng theo cách đồng nhất.
Thậm chí còn có những kiến trúc phức tạp, nơi việc truy cập vào một số vùng bộ nhớ nhất định tốn thời gian không cố định, khác nhau đối với mỗi nhân. Đặc tính kiến trúc này được là (NUMA - Non-Uniform Memory Access). Đây thường là trường hợp của các hệ thống đa socket (lắp nhiều chip CPU riêng biệt).
Hiệu năng giảm đi khi có nhiều tiến trình hơn nếu kích thước mảng vượt quá cache L2, vì các nhân bắt đầu tranh giành cache L3 dùng chung và RAM.
Saturating Bandwidth
RAM hiện đại có thể băng thong tới 40-60 GB/s => 1 nhân đơn lẻ luôn “đói” dữ liệu trong khi đường truyền RAM vẫn còn thừa chỗ. Khi thêm nhân, tổng số yêu cầu gửi đến RAM tăng lên, có thê bi nghẽn “cửa ngõ” L3 để ra RAM
CPU Affinity
Trong các CPU hiện đại, các nhân được chia thành các cụm (Clusters/CCX). Mỗi cụm có bộ đệm L3 Cache dùng chung riêng => Nếu có 2 tác vụ nặng về băng thông, hãy gán chúng vào 2 cụm khác nhau (ví dụ Core 0 và Core 4). Mỗi tác vụ sẽ có một “lối đi riêng” (L3 riêng) ra RAM, tránh việc xếp hàng chờ đợi tại một cửa ngõ duy nhất.
Discussion
Sign in with GitHub to comment or react. Powered by giscus.