AoS and SoA
AoS and SoA
AoS and SoA
- Array of Structures (AoS): Mỗi phần tử là một “struct” chứa nhiều trường => struct được đặt liên tiếp nhau trong bộ nhớ
- Structure of Arrays (SoA): Mỗi trường được tách thành một mảng riêng => Khi cần xử lý một trường trên toàn bộ dữ liệu, SoA rất tiện. Nhưng nếu cần nhiều trường cùng lúc, phải nạp nhiều cache line hơn → chậm hơn.
const int M = N / D; // số lần truy cập bộ nhớint p[M], q[M][D];// int p[M], int q[D][M];// Với AoS: q[M][D] → dữ liệu của một phần tử nằm liên tiếp.// Với SoA: q[D][M] → dữ liệu của một trường nằm liên tiếp, nhưng các trường của cùng một phần tử bị tách ra.iota(p, p + M, 0); // p = [0, 1, 2, ..., M-1]random_shuffle(p, p + M); // trộn ngẫu nhiên pint k = p[M - 1]; // bắt đầu từ một vị trí ngẫu nhiên
for (int i = 0; i < M; i++) { q[k][0] = p[i]; // gán giá trị vào q[k][0] for (int j = 1; j < D; j++) q[i][0] ^= (q[j][i] = rand()); // tạo dữ liệu ngẫu nhiên, đồng thời xor vào q[i][0] k = q[k][0]; // cập nhật k theo giá trị vừa gán}for (int i = 0; i < M; i++) { int x = 0; for (int j = 0; j < D; j++) x ^= q[k][j]; // tính xor của D trường k = x; // cập nhật k}==> vì các D trường của một phần tử nằm liên tiếp, CPU chỉ cần nạp ít cache line hơn => Khi D lớn AoS có thể nhanh hơn nhiều lần.
-
Temporary Storage Contention: nếu kích thước 𝑁/𝐷 là một lũy thừa lớn của 2, nhiều địa chỉ tạm thời sẽ ánh xạ vào cùng một cache line => cache phải liên tục nạp lại từ bộ nhớ ngoài → hiệu năng giảm mạnh
-
Huge Pages: Thông thường giúp giảm overhead quản lý bộ nhớ, giảm độ trễ tổng 10–15%. Nhưng trong thí nghiệm, với 𝐷 = 64, hiệu năng lại tệ hơn gấp 10 lần. Nguyên nhân do: L3 cache dùng địa chỉ vật lý để đồng bộ giữa các core.
- Với trang 4KB, địa chỉ ảo phân tán ngẫu nhiên → giảm tranh chấp cache.
- Với huge pages, địa chỉ thẳng hàng hơn → nhiều dữ liệu cùng rơi vào một vùng cache → tranh chấp nặng. 👉 Đây là ví dụ hiếm hoi cho thấy huge pages có thể làm hiệu năng giảm thảm hại.
-
Padded AoS: thêm padding để mỗi phần tử chiếm nguyên một cache line (để lấy D trường, ta phải nạp đúng D cache line riêng biệt). Kỳ vọng hiệu năng sẽ chậm đi giống SoA. Tuy nhiên vẫn nhanh hơn 3 lần do cơ chế RAM vật lý.
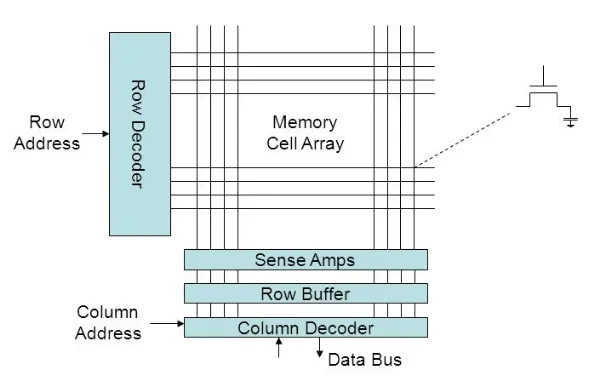
- RAM lưu dữ liệu trong ma trận tụ điện, chia thành hàng (row).
- Nếu 2 truy cập liên tiếp nằm cùng một hàng, ta có thể dùng row buffer mà không cần đọc/ghi lại toàn bộ => Dù padded AoS đặt mỗi phần tử ở cache line khác nhau, chúng vẫn thường nằm cùng một hàng RAM → tận dụng row buffer → tốc độ tăng.
👉 Điều này cho thấy: hiệu năng không chỉ phụ thuộc cache, mà còn liên quan đến cách RAM hoạt động ở mức phần cứng.
Bài tập
Câu hỏi tư duy
- Cho
struct Particle { float x, y, z, vx, vy, vz, mass; };và simulation cập nhật chỉ(x,y,z)mỗi tick. AoS hay SoA tốt hơn? Tính toán cache miss cho cả 2. - Khi nào AoS thắng SoA? Đưa workload cụ thể.
- SIMD vector hóa: tại sao SoA dễ vector hóa hơn AoS?
- AoSoA (hybrid) hoạt động thế nào? Khi nào tốt hơn cả AoS và SoA?
- Tại sao “padded AoS” trong example vẫn nhanh hơn SoA dù theo lý thuyết phải chậm bằng?
Bài tập code
Bài 1: Implement particle simulation 2 cách:
// AoSstruct Particle { float x, y, z, vx, vy, vz, mass; };struct Particle particles_aos[N];void update_aos(struct Particle* p, int n, float dt);
// SoAstruct Particles { float *x, *y, *z, *vx, *vy, *vz, *mass;};void update_soa(struct Particles* p, int n, float dt);Update: x += vx*dt; y += vy*dt; z += vz*dt;. Benchmark với N=10M, so sánh.
Bài 2: Compute kinetic energy 0.5 * mass * (vx² + vy² + vz²) cho mỗi particle. AoS hay SoA tốt hơn cho task này? Why?
Bài 3: Implement AoSoA: chia 8 particle thành 1 block, mỗi block là SoA của 8.
struct ParticleBlock { float x[8], y[8], z[8], vx[8], vy[8], vz[8], mass[8];};Benchmark vs pure SoA.
Đáp án
Câu hỏi tư duy
-
Particle= 28 byte. AoS array: cache line 64 byte chứa 64/28 = 2 particle (+8 byte waste). Update(x,y,z,vx,vy,vz)= 24/28 byte/struct → 86% useful data. Cache miss/particle ≈ 0.5 (2 particle/line). SoA: load 6 array (x,y,z,vx,vy,vz). Mỗi array có 16 float/cache line. Cùng truy cập 6 trường → 6 cache line/16 particle = 0.375 line/particle. Cache miss/particle ≈ 0.375. SoA thắng nhỏ (~25%). Nhưng nếu update tất cả 7 field: AoS = 0.5 line, SoA = 7/16 = 0.44 line — SoA vẫn thắng. -
AoS thắng khi: random access (game entity lookup by ID), tất cả field cần cùng lúc, working set nhỏ vừa cache. Ví dụ:
entities[id].health -= damage; entities[id].x += dx; ...→ 1 entity touch hết → AoS gom vào ít cache line nhất. -
SoA + SIMD: load 8 float
x[]liên tiếp vào 1 AVX register (single instruction). Computevx_vec * dt_vec. AoS phải gather (vgatherdpschậm 5–10x) hoặc transpose từng struct. SoA = “naturally vectorized”. -
AoSoA: array of (struct of array of size N=8 hoặc 16). Mỗi block = 1 SIMD width. Lợi ích:
- SIMD-friendly (như SoA).
- Locality cao trong block (như AoS) — 1 particle’s data vẫn gần nhau.
- Block size = SIMD width → no overhead. Dùng nhiều trong HPC, game physics, ML kernels.
-
RAM row buffer effect: padded AoS đặt mỗi struct trên cache line riêng (giống SoA về cache miss count). Nhưng các struct vẫn nằm liên tiếp trong cùng DRAM row → row buffer hit rate cao → memory access latency thấp hơn nhiều so với “thuần SoA” mà jump giữa nhiều array (nhiều DRAM row khác nhau). Đây là layer tối ưu thứ 3 (sau cache, sau virtual memory) — DRAM physics.
Bài tập code
Bài 1 — particle update:
// AoSstruct Particle { float x, y, z, vx, vy, vz, mass; };
void update_aos(struct Particle* p, int n, float dt) { for (int i = 0; i < n; i++) { p[i].x += p[i].vx * dt; p[i].y += p[i].vy * dt; p[i].z += p[i].vz * dt; }}
// SoAstruct Particles { float *x, *y, *z, *vx, *vy, *vz, *mass;};
void update_soa(struct Particles* p, int n, float dt) { for (int i = 0; i < n; i++) { p->x[i] += p->vx[i] * dt; p->y[i] += p->vy[i] * dt; p->z[i] += p->vz[i] * dt; }}Với -O3 -mavx2:
- AoS: compiler khó vector hóa do struct stride 28 byte (không match AVX 32 byte). Scalar loop. ~0.5–1 ns/particle.
- SoA: 3 separate vector loops, mỗi loop process 8 float/iter (AVX2). ~0.1–0.2 ns/particle. 3–5x faster.
Bài 2 — kinetic energy:
// SoA versionvoid ke_soa(struct Particles* p, float* ke, int n) { for (int i = 0; i < n; i++) { float v2 = p->vx[i]*p->vx[i] + p->vy[i]*p->vy[i] + p->vz[i]*p->vz[i]; ke[i] = 0.5f * p->mass[i] * v2; }}SoA tốt hơn ~3–4x. Lý do: 4 array (vx, vy, vz, mass) đều sequential → prefetcher hit, SIMD vectorize hoàn hảo. AoS phải gather 4 field từ struct stride 28 byte.
Bài 3 — AoSoA:
#define BLOCK 8
struct ParticleBlock { float x[BLOCK], y[BLOCK], z[BLOCK]; float vx[BLOCK], vy[BLOCK], vz[BLOCK]; float mass[BLOCK];};
void update_aosoa(struct ParticleBlock* blocks, int nb, float dt) { for (int b = 0; b < nb; b++) { for (int i = 0; i < BLOCK; i++) { // inner loop SIMD-able blocks[b].x[i] += blocks[b].vx[i] * dt; blocks[b].y[i] += blocks[b].vy[i] * dt; blocks[b].z[i] += blocks[b].vz[i] * dt; } }}Benchmark vs pure SoA: thường gần bằng (cùng SIMD-friendly). AoSoA thắng khi:
- Working set per block fit in L1 → tất cả 7 field của 8 particle = 224 byte ≈ 4 cache line, vừa L1.
- Cần truy cập multiple field per particle → 1 block load = nhiều field hit.
Pure SoA thắng khi: chỉ touch 1–2 field, working set trải qua nhiều cache line.
Discussion
Sign in with GitHub to comment or react. Powered by giscus.