Cache Associativity
Cache Associativity
Cache Associativity
// for (int i = 0; i < N; i += 256)for (int i = 0; i < N; i += 257) a[i]++;vòng lặp thứ hai nhanh hơn — gấp khoảng 10 lần, mọi bước nhảy là bội số của lũy thừa lớn của 2. Nguyên nhân ở cache associativity — cách CPU tổ chức bộ nhớ đệm.
Hardware Caches
-
Ở software thì policy focused on LRU (đơn giản và hiệu quả nhưng vẫn đòi hỏi một số thao tác dữ liệu không tầm thường). Ở hardware, policy này gọi là Fully Associative Cache va rất khó và tốn kém trong phần cứng
-
Direct-Mapped Cache: Mỗi khối dữ liệu trong RAM chỉ có thể nằm ở một vị trí duy nhất trong cache => Nếu hai địa chỉ khác nhau cùng ánh xạ vào một dòng cache, chúng sẽ liên tục thay thế nhau, giảm hiệu quả
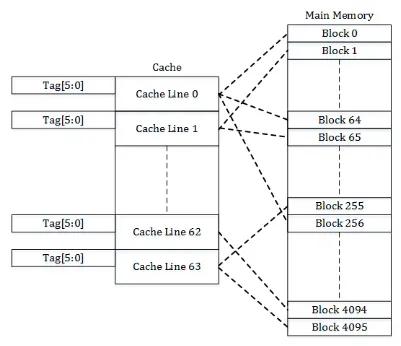
-
Set-Associative Cache: Ví dụ “2-way set-associative” mỗi nhóm có 2 cacheline. Khi dữ liệu mới vào nhóm, nó có thể chọn một trong 2 dòng. Nếu cả hai đều đầy, áp dụng LRU ==> Giảm bớt xung đột so với direct-mapped, nhưng vẫn dễ quản lý hơn fully associative. L3 cache của CPU có thể là 16-way set-associative
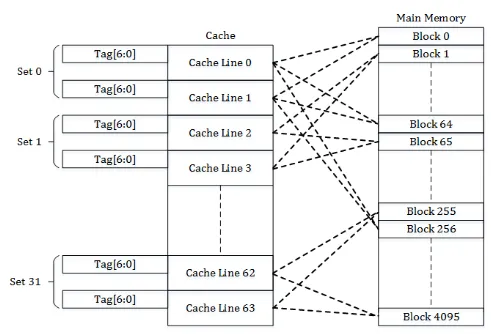
Address Translation
Cache ánh xạ địa chỉ bộ nhớ thành ba phần: nếu dung h àm băm như phần mêm thì quá chậm, nên lazy hơn:
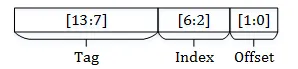
- Offset (6 bit thấp, bit 0–5): Vị trí trong 1 cache line (64 byte = 2⁶).
- Index (12 bit tiếp theo, bit 6–17): Xác định nhóm (set) nào trong cache L3 sẽ chứa dữ liệu — tổng cộng có 2¹² = 4096 nhóm.
- Tag (các bit còn lại): Phân biệt nhiều địa chỉ khác nhau cùng rơi vào 1 nhóm.
Hai địa chỉ khác nhau nhưng có cùng phần Index → cùng vào 1 nhóm cache → tranh giành chỗ nhau (cache thrashing).
Vấn đề khi bước nhảy là lũy thừa của 2
Bước nhảy thực tế tính bằng byte: \(256 \times 4 = 1024 \text{ byte} = 2^{10}\)
Cộng \(2^{10}\) vào địa chỉ tức là chỉ thay đổi các bit từ bit 10 trở lên, còn 10 bit thấp (bit 0–9) giữ nguyên.
Nhìn vào phần Index (bit 6–17):
- Bit 6–9 (4 bit thấp của Index): KHÔNG thay đổi vì bước nhảy \(2^{10}\) chỉ tác động từ bit 10 trở lên.
- Bit 10–17 (8 bit cao của Index): thay đổi qua mỗi lần nhảy.
Vậy Index chỉ có 8 bit thực sự thay đổi, 4 bit còn lại bị cố định. Số nhóm cache thực sự được dùng:
\(2^{12 - (10 - 6)} = 2^{12 - 4} = 2^8 = 256\) nhóm — thay vì toàn bộ \(2^{12}\) = 4096 nhóm
👉 Với bước nhảy 256: toàn bộ dữ liệu nhét vào 1/16 cache → dung lượng hiệu dụng giảm 16 lần → liên tục cache miss → đọc từ RAM → chậm hơn ~10 lần.
Với bước nhảy 257 (1028 byte, không phải lũy thừa 2): Index thay đổi tự nhiên qua đủ 4096 nhóm, dữ liệu phân tán đều, cache hoạt động đầy đủ → nhanh hơn nhiều.
Ví dụ
- Khi thực hiện binary search trên mảng có kích thước (2^{20}):
→ Thời gian trung bình ~ 360ns mỗi truy vấn. - Nhưng khi thực hiện trên mảng có kích thước (2^{20} + 123):
→ Thời gian trung bình chỉ ~ 300ns mỗi truy vấn. - Với mảng có kích thước đúng bằng lũy thừa của 2, các chỉ số “nóng” (các phần tử được truy cập nhiều nhất trong những lần đầu) thường cũng là bội số của lũy thừa 2.
- Điều này khiến nhiều địa chỉ ánh xạ vào cùng một dòng cache, dẫn đến việc chúng liên tục “đá” nhau ra ngoài.
- Kết quả: hiệu năng giảm khoảng 20% so với trường hợp kích thước mảng không phải lũy thừa của 2.
Lập trình viên thường thích dùng số mũ của 2 vì:
- Tính toán địa chỉ nhanh (dịch bit thay vì nhân chia).
- Modulo với số mũ của 2 dễ dàng (AND bit).
- Thuận tiện trong thuật toán chia để trị.
- Phổ biến trong benchmark.
Nhưng chính điều này lại tạo ra mẫu truy cập bộ nhớ xấu, khiến nhiều chỉ số ánh xạ vào cùng nhóm cache và liên tục “đá” nhau ra ngoài.
Cách khắc phục
- Tránh bước nhảy hoặc kích thước mảng là lũy thừa lớn của 2.
- Thay đổi một chút kích thước (ví dụ dùng 257 thay vì 256).
- Chèn “lỗ” trong layout bộ nhớ hoặc hoán vị chỉ số để phân tán dữ liệu.
Bài tập
Câu hỏi tư duy
- Cho L1 = 32KB, 8-way set-associative, cache line 64 byte. Tính số set. Bit nào trong địa chỉ là index, bit nào là tag?
- Tại sao L1 thường 8-way nhưng L3 có thể 16-way hoặc cao hơn?
- “Conflict miss” khác “capacity miss” thế nào? Cho ví dụ workload mỗi loại.
- Matrix transpose
B[j][i] = A[i][j]cho matrix1024×1024 float: tại sao đặc biệt chậm? Cách fix? - Tại sao stride 257 nhanh hơn stride 256 dù touch nhiều byte hơn?
Bài tập code
Bài 1: Đo cache associativity thrashing. Tạo array đủ lớn, loop với stride = 2^k cho k = 8, 9, 10, 11, 12, 13. Vẽ thời gian theo k. Knee ở đâu?
Bài 2: Matrix transpose:
void transpose_naive(float* B, const float* A, int n);void transpose_blocked(float* B, const float* A, int n, int block);Naive vs blocked với block size = 8, 16, 32, 64. So sánh.
Bài 3: Cho float a[1024][1024], viết loop tính sum += a[i][j] theo 2 cách:
- Row-major iteration
i,j - Column-major iteration
j,iĐo thời gian và giải thích.
Đáp án
Câu hỏi tư duy
-
Số set = 32KB / (64B × 8) = 64 set. Bit 0–5 = offset (64B = 2⁶). Bit 6–11 = index (64 set = 2⁶). Bit 12+ = tag. Vậy bit 12 trở lên discriminate giữa lines cùng set.
-
L1 phải nhanh (3-cycle latency) → ít way hơn để giảm comparison logic. L3 chậm hơn (40+ cycles), không nhạy với 1-2 cycle thêm cho associativity check → nhiều way hơn để giảm conflict miss. Cũng do L3 share giữa cores → cần associativity cao tránh cross-core thrashing.
-
Capacity miss: working set > cache size, không thể tránh. Conflict miss: cache còn chỗ trống nhưng do mapping nhiều địa chỉ vào cùng set → eviction sớm. Ví dụ:
- Capacity: scan 100MB array, L3 = 32MB → mỗi line miss 1 lần khi tới.
- Conflict: array 4MB, stride 4096 bytes (page size) → mọi access cùng set của L1 → thrashing dù total < L1.
-
Transpose 1024×1024 float = 4MB matrix. Inner loop
B[j][i] = A[i][j]: A access sequential (good), B access với stride 1024×4 = 4KB. Mỗi access B miss + index của B (bit 12 onwards) bằng nhau → cùng set L1. 1024 cột → 1024 access cùng vài set → thrashing. Fix: blocked transpose — chia matrix thành block 32×32, transpose từng block riêng. Block 32×32×4 = 4KB vừa L1, no thrashing. -
Stride 256 × sizeof(int)=4 = 1024 byte = 2¹⁰. Bước này không đổi 10 bit thấp → index của L1 chỉ thay đổi bit 10–11 → chỉ dùng được 4 set thay vì 64. Stride 257 × 4 = 1028 byte → index thay đổi đủ → dùng full 64 set, không thrash.
Bài tập code
Bài 1 — associativity benchmark:
#include <stdio.h>#include <stdlib.h>#include <time.h>
double bench(int* a, int n, int stride) { struct timespec t0, t1; clock_gettime(CLOCK_MONOTONIC, &t0); long ops = 0; for (int rep = 0; rep < 1000; rep++) { for (int i = 0; i < n; i += stride) { a[i]++; ops++; } } clock_gettime(CLOCK_MONOTONIC, &t1); double sec = (t1.tv_sec-t0.tv_sec) + (t1.tv_nsec-t0.tv_nsec)/1e9; return sec / ops * 1e9;}
int main(void) { const int N = 1 << 22; // 16MB int* a = aligned_alloc(64, N * sizeof(int)); for (int i = 0; i < N; i++) a[i] = 0; for (int k = 4; k <= 16; k++) { int stride_pow2 = 1 << k; // power of 2 int stride_off = stride_pow2 + 1; // offset by 1 printf(“stride=2^%-2d (%6d): pow2=%.2f off=%.2f ns/op\n”, k, stride_pow2, bench(a, N, stride_pow2), bench(a, N, stride_off)); }}Kết quả: pow2 stride chậm hơn off-by-1 stride, cực mạnh ở k = 10–14 (stride match L1/L2/L3 set count). Ngoài range này, both versions same speed.
Bài 2 — blocked matrix transpose:
void transpose_naive(float* B, const float* A, int n) { for (int i = 0; i < n; i++) for (int j = 0; j < n; j++) B[j*n + i] = A[i*n + j]; // B stride = n, terrible}
void transpose_blocked(float* B, const float* A, int n, int bs) { for (int ii = 0; ii < n; ii += bs) for (int jj = 0; jj < n; jj += bs) for (int i = ii; i < ii + bs && i < n; i++) for (int j = jj; j < jj + bs && j < n; j++) B[j*n + i] = A[i*n + j];}Với n=1024:
- naive: ~50ms (heavy thrash)
- blocked, bs=8: ~15ms
- blocked, bs=16: ~10ms
- blocked, bs=32: ~8ms (sweet spot, 32×32×4=4KB ≈ L1 portion)
- blocked, bs=64: ~10ms (block không vừa L1)
Bài 3 — row vs col iteration:
float a[1024][1024];
double sum_row(void) { double s = 0; for (int i = 0; i < 1024; i++) for (int j = 0; j < 1024; j++) s += a[i][j]; // sequential return s;}
double sum_col(void) { double s = 0; for (int j = 0; j < 1024; j++) for (int i = 0; i < 1024; i++) s += a[i][j]; // stride 4096 byte return s;}Row-major (C/C++ default layout): sum_row nhanh hơn ~10–20x. Lý do:
sum_row: liên tiếp memory → cache line 64B chứa 16 float → 1 miss / 16 access. Prefetcher hit perfectly.sum_col: stride 4096 byte = page size → mỗi access miss + có thể TLB miss. Ngoài ra 4096 = 2¹², có thể conflict miss trên L1.
Quy tắc: luôn iterate theo storage order. Trong C, inner loop = rightmost index. Trong Fortran/MATLAB (column-major): inner loop = leftmost.
Discussion
Sign in with GitHub to comment or react. Powered by giscus.